
Scaling GenAI with Amazon Bedrock and AgentCore
Building Secure, Production-Ready AI Agents
A comprehensive guide to deploying autonomous AI systems
Your team built an incredible AI prototype. Everyone's excited. Leadership wants it in production next quarter. Then reality hits, data privacy concerns, compliance requirements, scalability questions, and a security team that hasn't approved anything AI-related yet.
Enterprise AI adoption is growing year-over-year, but most organisations struggle to move beyond pilots. The gap between "impressive demo" and "production system" has never been wider.
The solution? Amazon Bedrock and Bedrock AgentCore.
The Enterprise AI Deployment Challenge
Here's what you should know:
The Infrastructure Problem: Building and maintaining GPU clusters is expensive and complex. Model hosting, versioning, and scaling require specialised expertise most teams don't have.
The Security Problem: Public AI APIs mean your data leaves your environment. For regulated industries handling customer data, this is a non-starter.
The Integration Problem: Your AI needs to connect with existing systems—databases, APIs, legacy applications. Most solutions leave you to figure this out yourself.
The Governance Problem: Who's responsible when AI makes a wrong decision? How do you audit AI actions? How do you ensure compliance with industry regulations?
Amazon Bedrock and AgentCore solve all of these.

What Is Amazon Bedrock Really?
Amazon Bedrock is a fully managed service providing unified access to foundation models from leading AI providers through a single API.
If you are not at the scaling stage of your agents you can start with reading: AI Agent Based Payment Infrastructure with AWS Bedrock.
Instead of building infrastructure or managing multiple vendor relationships, you get:
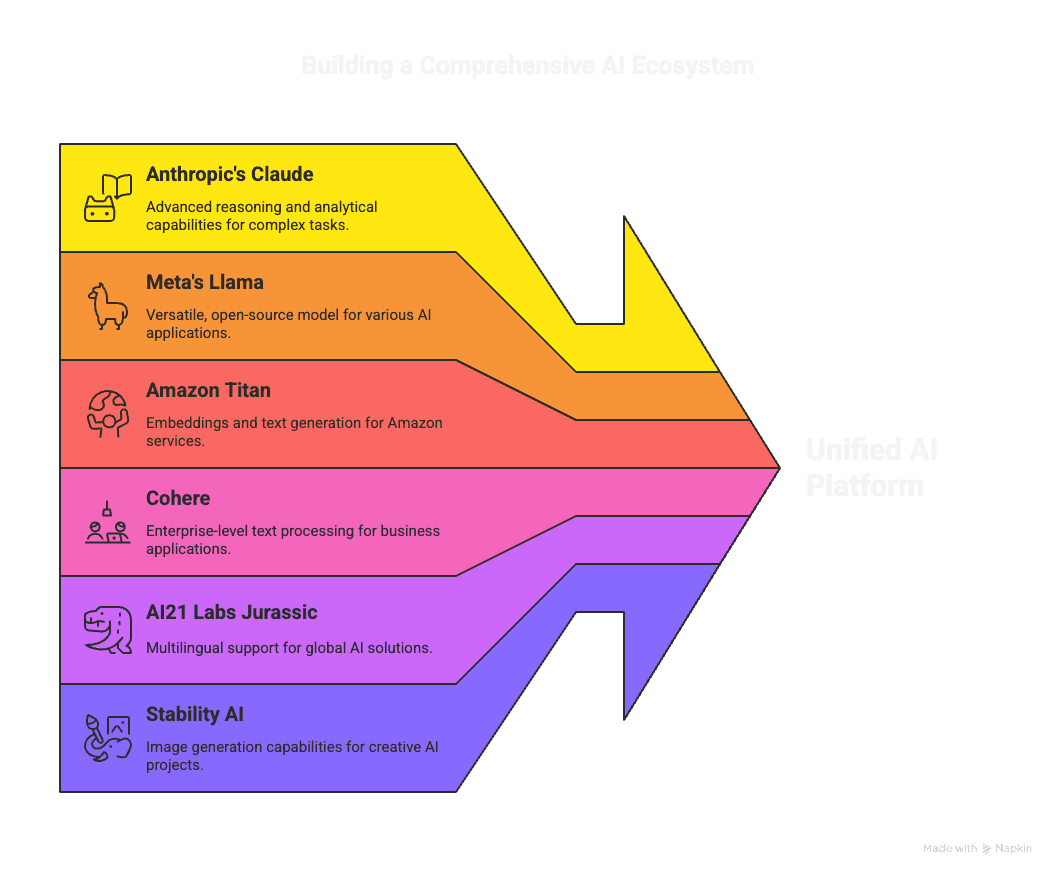
Multiple Foundation Models:
Anthropic's Claude (complex reasoning and analysis)
Meta's Llama (versatile, open-source tasks)
Amazon Titan (embeddings and text generation)
Cohere (enterprise text processing)
AI21 Labs Jurassic (multilingual applications)
Stability AI (image generation)
Fully Managed Service: No servers to provision, no infrastructure to maintain, automatic scaling based on demand.
Enterprise Security: Your data stays in your AWS environment. Bedrock doesn't use your prompts or completions to train models—critical for handling sensitive information.
Why Bedrock Changes the Game
Model Flexibility Without Vendor Lock-In
Different tasks require different models. Bedrock lets you choose the right tool for each job:
Claude for complex reasoning and document analysis
Titan for generating embeddings and semantic search
Stable Diffusion for image generation
Cohere for multilingual text processing
Switch between models via API calls, no infrastructure changes required.
Privacy-First Architecture

Your data never leaves your VPC. All processing happens within your AWS environment, with:
Encryption at rest and in transit
Full IAM integration for access control
CloudTrail logging for complete audit trails
VPC endpoints for private connectivity
This isn't just good practice it's what your compliance team demands.
Customisation That Actually Works
Fine-tune models with your proprietary data or implement Retrieval-Augmented Generation (RAG) to ground AI responses in your specific business context.
RAG is particularly powerful: instead of sending everything to the model, you retrieve only relevant information on-demand from your knowledge base, keeping context windows lean and responses accurate.
Understanding Bedrock AgentCore
Here's where things get interesting.
Bedrock provides the models. AgentCore lets you build autonomous agents that reason, plan, and execute multi-step workflows.
What Makes AgentCore Different?
Traditional chatbots respond to queries. AgentCore agents are autonomous systems that:
Reason About Problems: Break complex tasks into actionable steps Execute Actions: Call APIs, query databases, interact with AWS services Observe Results: Check if actions succeeded and adjust course accordingly Maintain Context: Remember conversation history and previous decisions
The ReAct Framework
Under the hood, AgentCore implements Reasoning and Acting (ReAct):
Thought: Agent reasons about what it needs to do
Action: Agent executes a specific action
Observation: Agent examines the results
Iteration: Agent repeats until the task is complete
Example workflow:
Thought: I need to check the customer's order status
Action: Query order database with customer ID
Observation: Order #12345 shipped yesterday via DHL
Thought: Now I need tracking information
Action: Call shipping API with order number
Observation: Package in transit, delivery expected tomorrow
Thought: I have all information needed
Action: Compose response to customer
This transparent reasoning makes debugging and auditing straightforward.
Action Groups and Knowledge Bases
AgentCore connects to your systems through:
Action Groups: Define what your agent can do—query databases, call APIs, execute Lambda functions, update systems.
Knowledge Bases: Connect agents to your documentation, policies, and reference materials using RAG. Agents retrieve relevant information automatically without manual prompt engineering.
5 Production-Ready AI Agent Patterns
1. The Intelligent Research Assistant
Your teams spend hours gathering information from multiple sources. Research agents automate this entirely.
How it works:
Receives research requests in natural language
Searches multiple knowledge bases simultaneously
Synthesises findings into coherent reports
Cites sources for fact-checking
Adapts search strategy based on initial findings
Real-world impact: What took analysts a full day now takes 10 minutes, with consistent quality and complete documentation.
2. The Customer Support Orchestrator
Support tickets pile up. Agents can handle routine inquiries autonomously while escalating complex issues with full context.
The agent:
Analyses customer inquiry intent
Retrieves account and order information
Searches knowledge base for policies
Generates personalised responses
Creates support tickets when needed
Routes to humans with complete context
Result: 40% of inquiries resolved automatically, average response time cut by 60%, customer satisfaction improved.
3. The DevOps Automation Expert
Infrastructure issues require quick diagnosis and remediation. DevOps agents provide 24/7 monitoring and automated response.
What it does:
Monitors CloudWatch metrics continuously
Correlates alerts across services
Diagnoses root causes automatically
Suggests or executes remediation steps
Documents all actions for audit trails
Example: Agent detects elevated error rates, identifies failing Lambda function, checks recent deployments, and suggests rollback—all within minutes.
4. The Compliance Monitoring Guardian
Ensuring continuous compliance with regulations is exhausting. Compliance agents provide real-time oversight.
The agent monitors:
Data access patterns for anomalies
Configuration changes against policies
API calls for compliance violations
Documentation for regulatory requirements
Outcome: Proactive compliance monitoring, instant alerts for violations, complete audit documentation.
5. The Content Generation Pipeline
Creating content at scale requires coordination between multiple steps. Content agents orchestrate end-to-end workflows.
The workflow:
Drafts content based on parameters
Fact-checks against internal databases
Applies brand guidelines automatically
Routes for human review if needed
Publishes to appropriate channels
Impact: Consistent brand voice, faster content production, reduced manual review burden.
Building Your AI Agent Architecture
Here's your technical blueprint but if you are already in production you can review your AI architecture and gain insights into where you need to improve the architecture and monitor your system with an Ai Architecture Assessment.
The Technical Stack
Core Components:
Amazon Bedrock → Foundation models and agent runtime
AWS Lambda → Serverless execution for agent actions
Amazon EventBridge → Event-driven agent triggering
AWS Step Functions → Complex workflow orchestration
Amazon S3 → Document storage for knowledge bases
Amazon OpenSearch → Vector database for embeddings
Amazon DynamoDB → Agent state and conversation history
Event-Driven Architecture
Build agents that respond to business events:
CustomerInquiry → Support agent activates
OrderPlaced → Fraud agent screens transaction
ConfigChange → Compliance agent validates
ErrorDetected → DevOps agent diagnoses
This event-driven approach ensures agents only consume resources when actually needed.
Retrieval-Augmented Generation (RAG)
Instead of cramming everything into prompts, implement RAG:
Store knowledge in S3 or OpenSearch
Compute embeddings for efficient semantic search
Retrieve relevant context for each query
Generate responses with current, accurate information
Benefits: Smaller context windows, lower costs, more accurate responses, easy knowledge updates.
Architecting for Production
When deploying AI agents to production, these three pillars are absolutely critical.
1. Observability: See Everything
Treat AI agents like critical microservices:
Essential Monitoring:
Amazon CloudWatch for metrics and alerts
AWS X-Ray for distributed tracing across agent actions
Custom business metrics (agent decisions, execution times)
End-to-end request tracking with correlation IDs
Key Metrics:
Agent response latency
Action success rates
Model token consumption
Error rates by agent type
2. Guardrails: Stay Safe
Bedrock's built-in guardrails provide multiple safety layers:
Content Filtering: Block harmful, toxic, or inappropriate outputs PII Detection: Prevent sensitive information leakage Topic Restrictions: Keep agents within defined domains Custom Validation: Enforce business-specific rules
Example: Prevent customer support agents from making unauthorised refunds or sharing competitor information.
3. Cost Optimisation: Spend Smart
AI costs can spiral quickly without proper controls:
Optimisation Strategies:
Right-size models for each task (don't use Claude Opus for simple classification)
Limit context windows to essential information
Cache frequent queries to avoid redundant model calls
Set usage quotas and budget alerts
Monitor "AI cost per business outcome" as key metric
Pro tip: Track cost per conversation, cost per resolution, or cost per report generated.
Your Implementation Roadmap
Let's walk through an architecture that brings all these components together.
Phase 1: Foundation Setup (Week 1-2)
Establish Infrastructure:
Set up AWS accounts and VPC configuration
Configure IAM roles with least privilege
Implement CloudTrail and CloudWatch logging
Create EventBridge event buses
Build Knowledge Base:
Identify critical documentation and policies
Structure information for RAG retrieval
Compute embeddings and store in OpenSearch
Test retrieval accuracy
Phase 2: First Agent Deployment (Week 3-4)
Start with Simple Use Case:
Document current manual process
Define agent actions and knowledge requirements
Build agent with single action group
Deploy in shadow mode alongside existing process
Example: Customer inquiry agent that provides information but doesn't take actions yet.
Phase 3: Action Integration (Week 5-6)
Connect to Systems:
Define Lambda functions for agent actions
Implement error handling and retries
Add agent authorisation controls
Enable agents to execute approved actions
Example: Allow agent to create support tickets, update customer records, send notifications.
Phase 4: Orchestration Layer (Week 7-8)
Build Complex Workflows:
Use Step Functions for multi-step processes
Implement human-in-the-loop for high-risk decisions
Add parallel agent execution for performance
Create fallback paths for failures
Phase 5: Production Scaling (Week 9+)
Expand Capabilities:
Deploy additional agent types
Increase automation levels gradually
Implement continuous learning from outcomes
Scale infrastructure based on demand
Avoiding Common Pitfalls
Latency Traps
The Problem: Sequential agent calls add up quickly, breaking SLA requirements.
The Solution:
Run independent agent actions in parallel
Use smaller, faster models for time-sensitive paths
Set strict latency budgets (e.g., <500ms for customer-facing)
Cache frequent queries aggressively
Data Privacy Risks
The Problem: Accidentally sending PII or sensitive data to models.
The Solution:
Implement data masking before agent processing
Use tokens instead of actual values where possible
Enable Bedrock guardrails for PII detection
Encrypt all data at rest and in transit
Regular security audits of agent prompts
Orchestration Deadlocks
The Problem: Agents waiting on each other create circular dependencies.
The Solution:
Define clear agent boundaries and responsibilities
Implement timeouts for all agent actions
Use correlation IDs for debugging
Build graceful degradation paths
Test failure scenarios explicitly
Context Window Overflow
The Problem: Trying to fit too much information in prompts, causing errors or truncation.
The Solution:
Implement RAG to retrieve only relevant information
Summarise lengthy documents before sending to agents
Split large tasks across multiple agent calls
Monitor token usage per request
Key Metrics to Track
Monitor these KPIs to measure AI agent success:
Performance Metrics:
Average agent response time
Task completion rate
Human escalation percentage
Error rate by agent type
Business Metrics:
Cost per agent interaction
Time saved vs manual process
Customer satisfaction scores
Resolution quality metrics
Operational Metrics:
Model token consumption
API call volumes
Infrastructure costs
Agent availability/uptime
Set up dashboards showing these metrics in real-time. Review weekly initially, then monthly as systems stabilise.
Your Next Steps: From Prototype to Production
Start Small, Think Big
To accelerate your time-to-market explore our AI Architecture Membership plans to help you progress faster.
Identify High-Impact Use Cases:
Review manual processes consuming significant time
Look for repetitive tasks requiring information gathering
Find workflows with clear decision criteria
Prioritise customer-facing improvements
Build Focused Proof of Concept:
Choose single, well-defined use case
Build MVP agent in 2 weeks
Deploy in shadow mode initially
Collect feedback and iterate
Prepare Your Team
Skill Development:
Train developers on prompt engineering techniques
Establish agent design patterns and standards
Create runbooks for agent monitoring
Build feedback loops for continuous improvement
Governance Framework:
Define agent approval process
Establish data governance policies
Create escalation procedures
Document compliance requirements
If you need to perform an analysis on your infrastructure and you are using AWS start with the AI Infrastructure scan
Measure and Iterate
Define Success Criteria:
Set baseline metrics before deployment
Establish target improvements
Define acceptable error rates
Plan for gradual automation increase
Continuous Improvement:
Monitor agent decisions regularly
Adjust prompts based on outcomes
Update knowledge bases as policies change
Stay current with new Bedrock features
Continuous improvement will help monitor your agents to discover how successful are the outcomes. You can do this with the AI Architecture Assessment.
The future is already here. Autonomous.
The question isn't whether to adopt AI agents—it's how quickly you can implement them safely and effectively.
With Amazon Bedrock providing the secure, scalable foundation and AgentCore enabling autonomous workflows, you can transform operations from reactive to proactive, from manual to autonomous.
The organisations that master AI agent deployment today will define the competitive landscape tomorrow.
Ready to get started with AI agents? Check out the AI Architecture Membership plans and further reading here: AWS Bedrock documentation, explore the Bedrock AgentCore guide, and review AWS compliance programs.
Join Our Exclusive Cloud Strategy Partnership
Ready to take your organisation's cloud strategy to the next level? Join our invitation-only CEO Cloud Strategy Partnership. Members receive quarterly strategic briefings, access to our proprietary cloud optimisation frameworks, and priority consulting with an AWS Certified Architect.
Our premium membership waiting list is now open for Q2 2026. Request an invitation today to secure your organisation's place at the forefront of cloud innovation.




