Before answering that question, it's worth asking a prior one — whether the cost problem is a tooling gap or an accountability gap. They have different solutions.
Yes many organisations can reduce AWS spending by 30-45% within 90 days without making architectural changes, provided the issue is operational waste rather than structural inefficiency. The distinction is crucial as these problems require different solutions. Operational waste includes over-provisioned resources and idle environments, which can be addressed through a disciplined approach: right-sizing resources, optimising purchases via commitments, and automating the removal of orphaned infrastructure. This approach leads to significant cost savings and provides insight into deeper architectural inefficiencies if costs rebound after initial optimisations. The article outlines a comprehensive three-pillar framework to achieve substantial savings and offers guidance on when architectural redesign may be necessary.
When Flexera analysed cloud spending patterns in 2024, they found that 32% of cloud costs go to pure waste: over-provisioned instances, forgotten test environments, idle databases running round-the-clock. For a company spending £1 million annually on AWS, that's £320,000 paying for nothing.
Yet when those same companies attempt cost optimisation, many see costs drop temporarily—then rebound within months. Why? Because 48% of developers don't track idle resources, and 75% of organisations can't even attribute costs accurately enough to know where money goes.
The real question isn't whether you can optimise without redesign. It's whether your specific cost problem stems from operational sloppiness or architectural misalignment. One fixes itself with better practices. The other requires rethinking how systems fit together.
Here's how to know which one you have—and what to do about it.
Two Types of Cloud Cost Problems (And Why Most People Confuse Them)
Operational waste accumulates from daily decisions: choosing a 16-vCPU instance "to be safe" when 4 vCPUs suffice, leaving development environments running through weekends, paying on-demand rates for workloads that run 24/7. These habits compound into millions of wasted pounds—but they're fixable without touching application code.
Architectural inefficiency runs deeper: always-on systems handling variable workloads, tightly-coupled services forcing everything to scale together, chatty designs multiplying data transfer costs. When waste is embedded in how systems work together, tactical optimisation provides temporary relief before costs climb back.
The difference shows up in what happens after you optimise. Operational waste stays fixed. Architectural problems reappear within 3-6 months as usage grows.
The framework below does both eliminates operational waste whilst revealing whether architectural issues exist underneath. Either way, you're ahead of where you started.
The Three-Pillar Optimisation Framework (No Architecture Changes Required)
Organisations achieving 30-45% cost reduction without architectural change focus on three areas: right-sizing resources to match actual usage, purchasing optimisation through commitments, and automated elimination of orphaned infrastructure.
Each pillar independently delivers 10-15% savings. Combined, they compound to 30-45% total reduction—if operational waste is your primary problem. If architectural issues exist, you'll see the savings initially, then watch costs creep back up as the underlying structure reasserts itself.
Think of it as a diagnostic test that pays you to take it. Best case: you fix the problem permanently. Worst case: you save money for 90 days whilst discovering you need deeper changes.
Pillar One: Resource Right-Sizing—The 15-25% Quick Win
Right-sizing means adjusting resource specifications to match actual requirements rather than theoretical capacity. An engineer provisions an r5.4xlarge instance with 16 vCPUs and 128GB memory for an application that actually uses 4 vCPUs and 32GB. That single choice costs £3,000-4,000 annually per instance.
Multiply that pattern across your infrastructure, and over-provisioning becomes your largest cost centre. The data confirms it: 48% of developers don't track idle resources, and 61% don't rightsize instances.
Establishing Your Utilisation Baseline
You need accurate utilisation data before changing anything. This means deploying CloudWatch agents for memory metrics (AWS doesn't track this automatically) and examining patterns over 14-30 days.
CPU utilisation: An instance consistently at 15% CPU is massively over-provisioned. One averaging 60% with spikes to 90% during business hours is appropriately sized—that headroom prevents performance degradation.
Memory utilisation: Requires the CloudWatch agent. Many organisations skip this step and optimise based solely on CPU, missing substantial savings. An instance might show acceptable CPU whilst wasting 70% of its memory allocation.
Network and storage patterns: An RDS instance provisioned with 10,000 IOPS but consistently using 800 IOPS wastes thousands of pounds annually.
The Right-Sizing Decision Framework
Critical under-utilisation (below 20% average): Immediate downsizing candidates. An r5.2xlarge at 12% CPU could move to r5.large at one-quarter the cost—£4,000-6,000 annual savings per instance. Organisations running 50+ under-utilised instances recover £200K+ annually from this alone.
Moderate under-utilisation (20-40% average): Evaluate peak patterns. If peaks are infrequent and non-critical, downsize. If frequent and business-critical, maintain current sizing or implement auto-scaling.
Optimal utilisation (40-70% average): Generally well-sized. Focus efforts elsewhere.
High utilisation (above 70% average): Assess whether consistent high utilisation creates performance risks. If regularly hitting 90-95%, you may be under-provisioned.
Implementation Without Disruption
Non-critical environments: Schedule changes during maintenance windows. Development, testing, and staging environments typically tolerate brief interruptions and frequently show the worst over-provisioning.
Production systems: Implement blue-green deployments. Launch right-sized instances, shift traffic, validate performance, then terminate oversized instances. This eliminates downtime whilst providing immediate rollback capability.
Databases: RDS instance modifications occur during maintenance windows with minimal downtime. Enable Enhanced Monitoring first to validate patterns before changing instance types. A single db.r5.4xlarge downgraded to db.r5.xlarge saves £15,000-20,000 annually.
Expected Impact
15-25% overall cost reduction
£15-25K savings per £100K annual spend
30-45 day implementation timeframe
Zero architectural changes required
Pillar Two: Purchasing Optimisation—Capturing the 20-30% Commitment Discount
Every EC2 instance and RDS database running on-demand pricing carries a 40-70% premium compared to commitment-based pricing. For stable, predictable workloads, paying on-demand rates means volunteering to overpay by half.
Yet 58% of developers don't use Reserved Instances or Savings Plans. This represents tens of thousands of pounds in unnecessary spending for most organisations.
Reserved Instances vs Savings Plans: Strategic Selection
Reserved Instances provide the highest discount (up to 72% for 3-year commitments) but lock you into specific instance families, sizes, and regions. Use RIs for:
Database instances that never change (RDS, ElastiCache, Redshift)
Bastion hosts and NAT gateways running 24/7/365
Fixed infrastructure components that won't migrate
Savings Plans offer slightly lower discounts (up to 66% for 3-year commitments) but provide flexibility to change instance families and sizes. Use Savings Plans for:
Application servers that may scale or change instance types
Workloads that might migrate between regions
Infrastructure likely to evolve over the commitment period
Calculating Optimal Commitment Level
Step 1: Analyse baseline usage Examine consistent 24/7 usage over the past 90 days. Resources running continuously regardless of time or day represent safe commitment opportunities.
Step 2: Apply the 70% rule Commit to 70% of baseline usage, leaving 30% on-demand for flexibility. This protects against over-commitment whilst capturing majority discount. If baseline usage is £100K annually, commit to £70K worth of capacity.
Step 3: Layer commitments strategically Start with 1-year commitments for most infrastructure, reserving 3-year commitments for truly stable components like databases.
The Financial Engineering Advantage
Commitment-based purchasing transforms cloud spending from variable operational expense to semi-fixed capital allocation. This makes budgeting more predictable and demonstrates financial discipline.
For organisations with seasonal patterns, strategic commitment layering captures discounts during baseline periods whilst maintaining on-demand flexibility for peaks. A retailer might commit to baseline capacity year-round whilst running additional on-demand capacity during Q4—capturing 60-70% discount on baseline spend.
Expected Impact
20-30% reduction on committed workloads
£12-18K savings per £100K annual spend (assuming 60% workload commitment)
14-21 day analysis and implementation timeframe
No operational impact
Pillar Three: Automated Waste Elimination—Finding the Hidden 10-15%
The first two pillars address visible waste. The third targets invisible accumulation: orphaned resources, forgotten environments, zombie infrastructure.
An engineer spins up a test environment, validates functionality, moves on without cleanup. That environment runs indefinitely—costing £500-2,000 monthly whilst delivering zero value.
Common orphaned resources:
Unattached EBS volumes from terminated instances
Elastic IP addresses accruing hourly charges
Load balancers routing to terminated targets
Snapshots from deleted resources retained indefinitely
Old AMIs from deprecated applications
Research shows 48% of developers don't track and shut down idle resources. Engineering teams move fast, priorities shift, cleanup becomes nobody's explicit responsibility.
Implementing Automated Waste Detection
Unattached volume detection: Scan for EBS volumes without EC2 attachments older than 7 days. Automate deletion after 30-day warning period, saving £50-150 per volume annually.
Idle resource identification: Track EC2 instances with below 5% CPU utilisation over 7+ days. Automatic stop after 14 days with owner notification prevents accumulation.
Development environment scheduling: Running non-production environments only during business hours (60 hours weekly vs 168 hours) cuts cost by 64%—typically saving £20-40K annually for mid-sized organisations.
Snapshot lifecycle policies: Implement automatic deletion of snapshots older than retention requirements. A 90-day retention policy with automatic deletion eliminates indefinite storage costs.
The Tagging Imperative
Effective waste elimination requires knowing who owns what. Without accurate resource tagging, you cannot identify orphaned resources confidently or contact owners for remediation.
Implement mandatory tagging requiring:
Owner (email address of responsible engineer/team)
Environment (production, staging, development, testing)
CostCentre (department or project paying for resource)
Project (application or initiative the resource supports)
ExpiryDate (for temporary resources)
Resources created without required tags get automatically flagged, with automated termination after 7-14 days if tags aren't added.
Expected Impact
10-15% cost reduction from eliminated orphaned resources
£10-15K savings per £100K annual spend
30-60 day implementation
Ongoing value as waste prevention becomes systematic
The 90-Day Implementation Roadmap
Days 1-14: Discovery and Baseline
Week 1:
Install CloudWatch agents for memory and disk metrics
Enable AWS Cost Explorer and detailed billing
Deploy tagging audit to identify untagged resources
Establish current spend baseline by service and account
Week 2:
Collect 14-day utilisation data across EC2, RDS, ElastiCache
Identify under-utilised resources (below 20% average)
Document orphaned resources (unattached volumes, unused IPs)
Calculate theoretical savings from right-sizing
Days 15-45: Quick Wins Implementation
Week 3-4:
Right-size development and testing environments
Implement auto-stop schedules for dev/test infrastructure
Delete orphaned resources in non-production accounts
Validate changes don't impact engineering productivity
Week 5-6:
Begin with lowest-risk production changes
Right-size obviously over-provisioned instances (below 15% utilisation)
Implement changes during maintenance windows with rollback plans
Monitor performance post-change for 7 days before proceeding
Days 46-75: Purchasing Optimisation
Week 7-8:
Analyse 90-day usage patterns to identify baseline
Calculate optimal RI and Savings Plan commitments
Model financial impact of 1-year vs 3-year commitments
Obtain CFO approval for commitment spending
Week 9-10:
Purchase Reserved Instances for databases and fixed infrastructure
Activate Savings Plans for flexible compute workloads
Validate discount application in billing
Project annual savings from commitments
Days 76-90: Waste Automation and Governance
Week 11-12:
Deploy automated orphaned resource detection
Implement auto-stop for idle instances
Enforce tagging policies with automated compliance checks
Establish ongoing monthly optimisation review process
Expected Results by Day 90
Total cost reduction: 30-45%
Monthly savings: £25-45K per £100K annual spend
Annualised savings: £300-540K per £1M annual spend
Architecture changes: Zero
Code changes: Zero
Service disruption: Minimal, well-controlled
When Optimisation Stops Working: The Warning Signs
If you implement this framework diligently for 90 days and experience any of the following, you have architectural problems requiring redesign:
Costs rebound within 3-6 months You implement all tactics, costs drop 30%, then within a quarter they're back to original levels or higher. Inefficiency scales faster than optimisation can remove it.
Cost grows faster than business (still) Even after optimisation, cloud spend increases 30-40% whilst revenue grows 10-15%. Unit economics are broken at the architectural level.
Constant re-optimisation cycles Every quarter becomes a cost-cutting initiative. You're perpetually chasing waste instead of preventing it—the clearest signal architecture is the problem.
Teams can't scale independently When one service needs to scale, everything scales together. You're paying for capacity you don't need because components are architecturally coupled.
Multi-region or compliance requirements are impossible You need to expand geographically or meet new regulatory requirements, but your architecture wasn't designed for it. Retrofitting becomes prohibitively expensive.
The Redesign Decision
If 2 or more warning signals appear after implementing this framework, operational optimisation isn't your answer. You need architectural redesign.
Read our companion articles:
The rule: If optimisation tactics don't stick for 6+ months, architecture is your problem—not operations.
Common Implementation Pitfalls
Analysis Paralysis
The instinct is to analyse everything perfectly before making changes. This delays action whilst spending continues at current rates.
Solution: Set a 14-day analysis deadline. After two weeks of data collection, you have enough information to identify clear optimisation opportunities. Begin implementation whilst continuing to refine analysis.
Insufficient Testing
Right-sizing production resources without adequate testing creates performance risks that undermine confidence in the entire initiative. One degraded customer-facing service stops your cost optimisation program faster than any other factor.
Solution: Always implement changes with rollback plans. For critical production systems, use blue-green deployments allowing instant reversion. Test in non-production first, monitor closely post-change.
Ignoring Application Dependencies
Downsizing one component without understanding downstream dependencies cascades into broader performance issues. A right-sized database might perform adequately in isolation but create bottlenecks when application load increases.
Solution: Map dependencies before optimisation. Understand which components are bottlenecks, which have headroom, which might create downstream issues if performance decreases.
Treating Optimisation as One-Time Initiative
The biggest pitfall is treating cost optimisation as a project with an end date. Without ongoing attention, costs inevitably drift back upward.
Solution: Establish ongoing processes: monthly cost reviews, automated waste detection running continuously, quarterly optimisation sprints, engineering team cost accountability integrated into normal operations.
The Business Case
For an organisation spending £1 million annually on AWS:
Current annual spend: £1,000,000
Target reduction (35%): £350,000 annual savings
Implementation cost: £40,000-60,000 (tools, consulting, engineering time)
Net first-year benefit: £290,000-310,000
Ongoing annual benefit: £350,000 (years 2+)
Simple payback period: 1.7-2.5 months
This represents a 500-700% first-year ROI—substantially higher than most technology investments.
Every pound wasted on inefficient AWS infrastructure is a pound unavailable for innovation, new feature development, or hiring. For a technology organisation, efficient infrastructure spending directly enables faster growth.
Taking Action
Audit your current monitoring coverage—do you have CloudWatch agents deployed for memory metrics?
Enable AWS Cost Explorer if not already active and export the last 90 days of billing data
Conduct a tagging audit—how many resources lack proper owner, environment, and cost centre tags?
Calculate your waste baseline—if you're like most organisations, assume 30-35% of current AWS spending is waste
Planning Actions (Next 30 Days)
Establish your optimisation goals—define target cost reduction and timeline
Identify your optimisation owner—assign a senior technical leader to drive the initiative
Build your business case—calculate projected savings, implementation costs, and ROI
Create your 90-day roadmap adapted to your specific environment
The 90-Day Test
Implement this framework fully for 90 days. Then evaluate:
If costs stay down: Operational optimisation was your answer. Maintain FinOps practices and move forward.
If costs rebound: You have architectural problems. Don't waste another quarter fighting symptoms. Read our architectural redesign guides and take the assessment to understand what needs to change structurally.
Next Steps: Choose Your Path
Path 1: DIY Implementation Follow this framework yourself starting with the 14-day discovery phase.
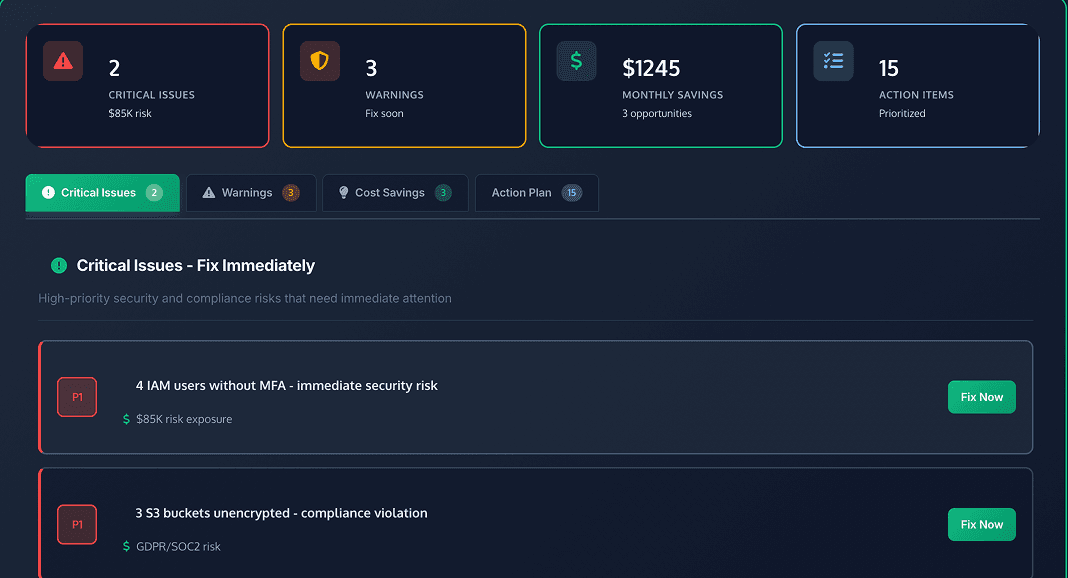
Path 2: AWS Cloud Assessment. Take our assessment to understand your specific situation: AWS Cloud Cost Assessment → Receive a scorecard with an action plan with access to your personalise dashboard.

Answer 6 questions and we'll tell you:
Whether operational optimisation will work for you
If architectural issues are already present
Your estimated savings opportunity
Recommended next steps for your specific situation
Path 4: AWS Cloud Architecture Design - Executive Cloud Advisory Membership delivers complete infrastructure audit, monthly architecture reviews, and automated waste detection setup. Learn More →
Start with the assessment. Know what you're dealing with. Then act.
Related Reading:
Published by AWS Solutions Architect Consulting